
最近本の画像からデータを収集するということを個人的にしています。
そこで青色のテキストだけ収集する必要が出てきたのでやり方を調べました。
順序は以下のとおりです。
・画像から特定の色のテキスト以外を取り除く(黒く塗りつぶしちゃう)
・次に、OCRにかけてテキストを抽出する
一つひとつみていきます。
画像から特定の色のテキスト以外を取り除く(黒く塗りつぶしちゃう)
今回は以下のサンプル画像から青色の文字列を取得することを目標にします。なので「色の」と、「取得する」をoutput.txtとして保存できればいいということになります。

コードは以下のような感じです。
import cv2 as cv
def main():
img = cv.imread('images/sample.jpg')
hsv = cv.cvtColor(img, cv.COLOR_BGR2HSV)
h,s,v = cv.split(hsv)
mask = cv.inRange(hsv, (80, 58,0), (140,255,255))
dst1 = cv.bitwise_and(img, img, mask=mask)
cv.imwrite("dst1.png", dst1)
if __name__ == '__main__':
main()色を取り出すときにhsvの範囲は自分である程度調整する必要があります。
まず、hsvのhueは色相を表します。大体の範囲は以下のx軸とおりです。今回は青色を検出したいので、80~140に設定しました。
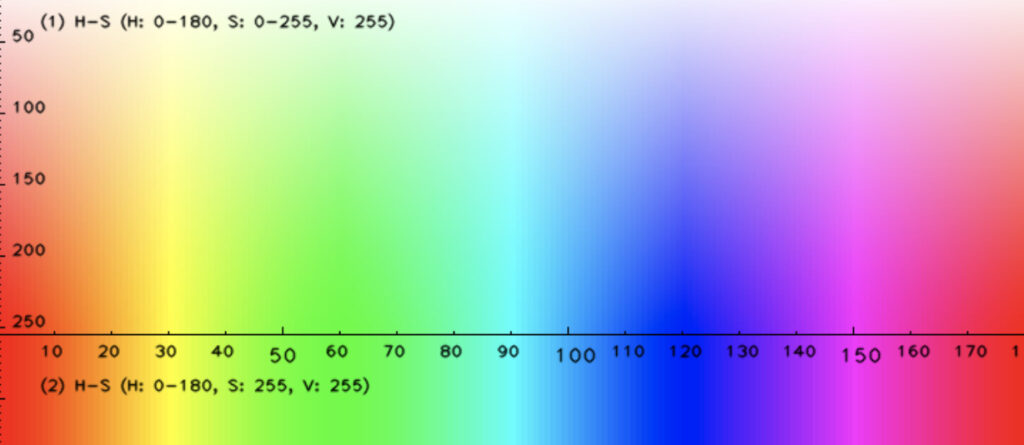
彩度(Saturation)」が一番調整が必要なところでした。僕の場合はinRangeの第2引数の第2引数(ここでは58)の部分を上げ下げしながら輪郭がはっきりするところを探しました。
70の時。

58の時。

30の時。

「明度(Value・Brightness)に関しては特にパラメータをいじる必要はないかと思います。
OCRにかけてテキストを抽出する
OCRをする方法としてpytesseractとかもあるんですけれども、ここではtesseractをbrewでインストールして使いました。理由としては、僕が抽出したかったのが韓国語のテキストだったのでpytesseractよりもtesseractの方が設定が楽だったからです。
tesseractがインストールされていない場合はインストールしてください。
brew install tesseract次に利用可能な言語を確認します。最初はeng osd snumの3つだと思います。
morinobuhiro ~ (work) % tesseract --list-langs
List of available languages (5):
eng
osd
snumこのままだと日本語が使えないので、以下のサイトにアクセスしてjpn.traindataをダウンロードします。
そしてダウンロードしたtraindataファイルをtessdataというフォルダに保存します。
morinobuhiro ~ (work) % brew list tesseract
/usr/local/Cellar/tesseract/4.1.1/bin/tesseract
/usr/local/Cellar/tesseract/4.1.1/include/tesseract/ (19 files)
/usr/local/Cellar/tesseract/4.1.1/lib/libtesseract.4.dylib
/usr/local/Cellar/tesseract/4.1.1/lib/pkgconfig/tesseract.pc
/usr/local/Cellar/tesseract/4.1.1/lib/ (2 other files)
/usr/local/Cellar/tesseract/4.1.1/share/tessdata/ (37 files)morinobuhiro ~ (work) % cp ~/Downloads/jpn.traineddata /usr/local/Cellar/tesseract/4.1.1/share/tessdata/
するとjpnが新たに追加されていることが確認できるかと思います。
morinobuhiro learn_scrapy (work) % tesseract --list-langs
List of available languages (6):
eng
jpn
osd
snumこれで無事tesseractで日本語のテキストが扱える様になったので、コマンドを実行します。
morinobuhiro learn_scrapy (work) % tesseract dst1.png output -l jpnoutput.txtの中身↓
色 の
取 得 す る
以上!